Zhipu opened the GLM-5.1 high-speed API on May 22, 2026, with an output speed of 400 tokens/s. Put that number in context: human reading speed is typically 3 to 5 tokens per second, meaning this API outputs text more than 80 times faster than you can read. In terms of feel, Quantum Bit’s hands-on description hits the mark: the model thinks for about ten seconds, and then code “spurts out.”
But 400 tokens/s itself isn’t the point. The point is what it reveals about an ongoing shift: the competitive axis of AI APIs is moving from “how smart is the model” to “how smart and fast.” In Agent, real-time coding, and voice interaction scenarios, the user isn’t waiting for a single response — they’re waiting for a continuous, flowing interaction loop. Every tool call, every code completion, every reasoning step is compressing the tolerable latency budget.
This article aims to make two things clear. First, what gets GLM-5.1 to this speed isn’t “optimizing harder,” but “changing the execution model.” The TileRT inference engine has been restructured at the execution model level. Second, why this shift has a structural impact on the entire AI API ecosystem.
The core idea behind TensorFlow’s static graph mode and TensorRT’s compiler optimization is to compile the computation graph ahead of time, making execution fast at runtime. At compile time, you can pre-plan memory allocation, fuse adjacent operators, and eliminate redundant computation.
But there’s an easily overlooked premise here: what compiler optimization primarily eliminates is startup overhead, not step boundaries.
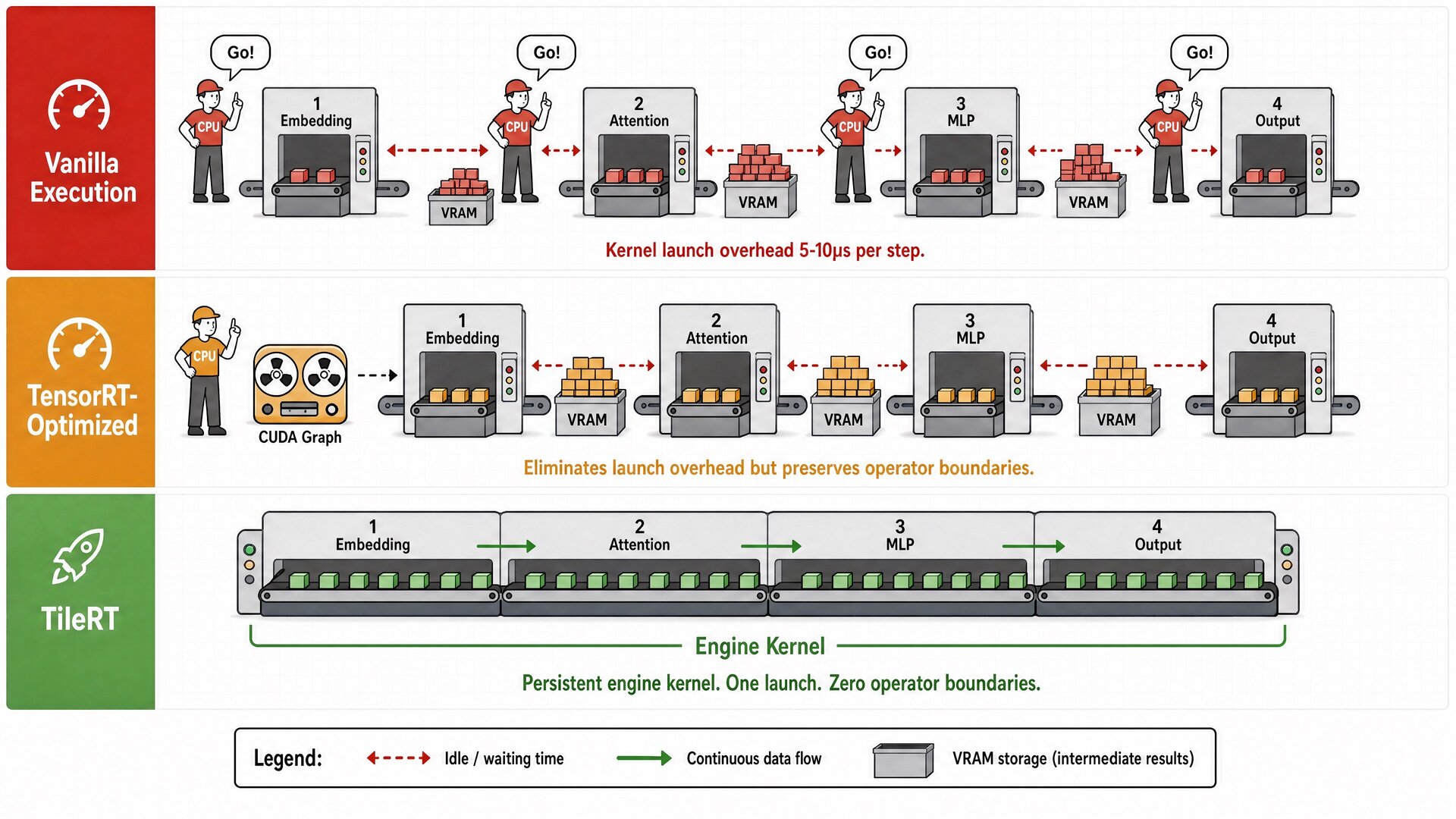
Imagine a factory where each station handles one process step: first cutting, then polishing, then assembly.
How traditional frameworks execute is equivalent to: the foreman shouts “start,” and the first station goes to work. After finishing an entire batch, all semi-finished products go into storage. The foreman shouts again, and the second station pulls semi-finished products from the warehouse to continue. The effect of compiler optimizations like TensorRT is equivalent to the foreman recording the instructions ahead of time and having them play back automatically, saving the time spent shouting. But it doesn’t change a fundamental fact: the product still needs to finish an entire batch at one station, go into storage, come out of storage, and then enter the next station.
When the batch size is large, this approach works fine. Each station is busy for a long time — tens or even hundreds of milliseconds. The transfer cost between stations, the few microseconds to go in and out of storage, is negligible by comparison.
But when the batch size is compressed down to near 1 — which is the norm for real-time interactive scenarios, generating one token at a time — things change. The actual processing time at each station plummets to microseconds, while the transfer cost between stations stays the same. The product spends only 2 microseconds at each station but takes 5 to 10 microseconds to transfer between stations. More than half the time is spent waiting for the next station to be ready, not processing the product.
This is exactly the discovery the TileRT team described in their technical blog: GPU utilization is high, theoretical compute power isn’t bad, but token generation speed just won’t go up. Because the bottleneck isn’t insufficient compute — it’s compute trapped in the gaps between stations.
On an 8×H200 NVL server, based on theoretical bandwidth, the decode ceiling is close to 1000 tokens/s. But real systems often only achieve tens of tokens/s. That’s an order of magnitude gap. Not because any single station is too slow, but because the whole factory spends half its time waiting for someone to shout “start.”
The core idea: transform the entire factory from a “batch processing workshop” to a “continuous pipeline.” The product no longer waits for an entire batch to finish before being pushed to the next station; instead, it flows piece by piece. As soon as one station finishes a piece, it passes it directly to the next — no need for warehouse in/out. The foreman shouts “start” only once for the entire production cycle, and from then on, all scheduling, synchronization, and handoffs happen internally within the workshop.
At compile time — before the model even starts running — TileRT pre-orchestrates the entire model’s computation flow, generating a continuously running assembly pipeline. At runtime, this pipeline is resident on the GPU and never exits; data flows continuously through all computation steps, and intermediate results are no longer repeatedly written back to and read from VRAM.
TensorRT’s compiler optimization operates at the station level: make each station faster, merge adjacent stations. But the isolation walls between stations remain. TileRT’s compilation operates at the factory level: it doesn’t just optimize each computation step — it orchestrates the entire computation flow as a single whole, eliminating the barriers between steps.
Once this continuous pipeline is running, three things can happen simultaneously.
First, pieces from different computation steps can advance in an interleaved fashion. Part of the attention result is computed, and the MLP can start processing immediately, without waiting for the entire attention computation to finish.
Second, data movement and computation can overlap. While the next batch of data is being moved, the current batch is still being computed.
Third, in multi-GPU scenarios, different GPUs no longer do the same work and then stop to synchronize. They take on different responsibilities based on their computation density — some specialize in index lookups, others in dense computation. Like different stations on an assembly line, each doing its own job, without everyone stopping to align.
The combined effect of these three things: the GPU no longer behaves like it’s constantly starting, stopping, starting, stopping. Instead, it’s more like a continuously running engine.
On a single B200 card, TileRT’s end-to-end decode speed for an MoE model is 1.48 times that of vLLM (batch size=1). Even more noteworthy is the warmup overhead: vLLM needs 123 seconds and SGLang needs 583 seconds to warm up and start, because they repeatedly perform JIT compilation and CUDA Graph capture at runtime. TileRT only needs 35 seconds — its orchestration is completed offline, and at runtime it just loads it. This has direct operational value in production environments that need frequent scaling up and down.
For the technical details of TileRT, there is an Event Tensor paper on arXiv that provides the complete academic formulation. The open-source code is at github.com/tile-ai/TileRT, though it should be noted that the repository currently only exposes the model definition at the Python layer; the core kernel compilation and scheduling engine are not yet fully open-sourced.
400 tokens/s is not something TileRT achieved on its own. GLM-5.1’s model architecture was designed with cooperation with the inference engine in mind from the start.
First, sparse activation. GLM-5.1 is an MoE model with 744B total parameters but only 40B parameters activated per token (see the GLM-5 technical report for details). It’s like a factory that only processes the parts needed for the current order, without having to go through the entire inventory. The per-step computation is naturally small, giving the inference engine room to maneuver between computation density and concurrency.
Second, multi-token prediction (MTP). Traditional autoregressive generation produces tokens one by one. Every time it produces one token, it has to run through the entire model. GLM-5’s approach is to train the model to predict the next 2 to 3 tokens simultaneously, and then the main model quickly verifies which ones are acceptable. In practice, it averages 2.76 tokens per step (DeepSeek-V3.2 achieves 2.55). In TileRT’s continuous pipeline mode, this means each pipeline cycle produces more output, and the fixed cost per cycle is amortized more effectively.
Third, sparse attention (DSA). In long-context scenarios, traditional attention computes correlations between every pair of tokens, with computation growing quadratically with context length. DSA lets the model determine which tokens are important and only performs attention computation on those, cutting computation by a factor of 1.5 to 2. The compute bandwidth saved is used by TileRT’s pipeline to cover data movement and communication time.
Sparse activation, multi-token prediction, and sparse attention — these are the contributions at the model level. But none of them alone reaches 400 tokens/s. Together, they form a positive feedback loop with TileRT: the pipeline mode means the verification step of multi-token prediction no longer introduces additional latency; MoE’s dynamic routing achieves load balancing within the GPU without requiring repeated CPU-side intervention; the compute bandwidth saved by sparse attention is just enough to mask communication latency. The engine and the model each provide headroom for the other’s design choices.
Now let’s place GLM-5.1 back into the industry landscape.
Current AI API speeds generally fall into three tiers.
If GLM-5.1’s 400 tok/s is genuine and comes from a general-purpose API, it means it has reached the order of magnitude of Mercury C at frontier intelligence levels, significantly ahead of all current mainstream API fast modes. But it should be noted that this figure has not yet been verified by independent benchmarks like Artificial Analysis, and Quantum Bit’s hands-on review explicitly stated that continuous verification under more conditions is needed.
The technical approaches different companies are taking for fast mode fall into four categories. Anthropic’s Fast Mode uses the same model but achieves a 2.5x speedup by adjusting inference configuration, at a cost of 6x the price. The model quality remains exactly the same, but the business model shifts from “selling intelligence” to “selling intelligence × speed.” Google’s Gemini Flash/Pro tiering involves training different-sized models to cover the speed-quality spectrum. Third-party providers like Fireworks take the inference optimization route — the same model can differ by 5 to 6x in speed across providers, relying on speculative decoding, quantization, and kernel optimization. Zhipu’s TileRT route is different from all three: it’s not about changing configurations, not about training smaller models, and not about optimizing existing frameworks — it’s about restructuring at the execution model level.
Why does the difference between these four approaches matter? Because it points to two different competitive logics.
“Quality competition” is about whose model scores higher on benchmarks. GLM-5.1’s 58.4% on SWE-bench Pro has already surpassed GPT-5.4’s 57.7%. But the ceiling of this type of competition is narrowing. The intelligence gap between frontier models is getting smaller, and benchmark scores are getting closer.
The logic of “quality × speed competition” is: when several models can all complete the same task, whoever does it faster wins. This logic is especially clear in programming scenarios. The user experience of Cursor or Claude Code doesn’t depend on how elegant the code the model writes is, but on how long it takes from issuing a command to seeing the first usable piece of code. If output speed goes from 40 tok/s to 400 tok/s, a 2000-token code snippet goes from 50 seconds of waiting to 5 seconds. In the former case, you get up to get a glass of water; in the latter, you just wait a moment.
Zhipu’s stock price rose more than 22% intraday on May 22. Although this was partly combined with the positive factors of an expected Hang Seng Tech Index inclusion and the Southbound Stock Connect qualification, 400 tokens/s is an effective market signal. Morgan Stanley predicts that after Zhipu is included in the Southbound Stock Connect, it could attract 43.9 billion HKD (about 5.6 billion USD) in southbound funds. Zhipu’s IPO cornerstone investment is about 3 billion HKD — the estimated southbound funds are 15 times that.
Looking at the industry landscape, inference speed is becoming the second competitive axis, and the trajectory parallels the inference cost competition from two years ago. DeepSeek V4 Pro just announced today that it is making its previous 75% promotional discount permanent — the API price becomes a quarter of what it was. This move itself is a signal of intensifying cost competition. When costs drop to the point where users become less price-sensitive, speed becomes the next dimension they frown about. Users no longer ask “why is it so expensive,” but “why is it still spinning.”
This is a classic bottleneck migration: inference cost was once the primary bottleneck; after costs came down, the bottleneck shifted to latency. When latency is also compressed, what might be the next bottleneck? Perhaps inference system reliability, KV cache management efficiency, or the coordination latency of multi-agent collaboration.
For AI programming tools, this shift has direct product implications. The difference between 100 tok/s and 400 tok/s is not a 4x “faster” — it’s a switch in interaction paradigm from “passively waiting for AI to write code” to “watching the code flow together with AI.” User retention, usage frequency, and task completion rates will differ by orders of magnitude between these two modes.
For Zhipu, choosing “speed × quality” instead of continuing to cut prices is a differentiated path. DeepSeek has already pushed prices extremely low, and the marginal returns from continuing to compete on price are limited. Meanwhile, there is a genuine product demand gap in speed: every company building Agents, programming tools, and real-time interactions is demanding faster inference. This may explain why TileRT currently only serves enterprise clients: high-frequency, low-latency enterprise workloads are the most effective testing ground for a “speed × quality” strategy.
The TileRT team made a judgment in their blog: “Speed itself becomes a scaling law.”
The logic behind this judgment is: under the Test-Time Scaling paradigm, models improve answer quality through more inference steps, and inference speed directly affects the reasoning depth a model can achieve in a fixed amount of time. Given the same 10 seconds, a model running at 400 tokens/s can explore more reasoning paths, perform more self-verification, and ultimately may produce higher quality answers. Speed is no longer just a nice-to-have that affects user experience — it becomes a parameter that directly influences model capability.
This logic can be generalized. If an Agent’s execution time is compressed from minutes to seconds, the Agent can do more rounds of trial and error, more environment interactions, and more self-correction. When AI programming tool responses go from visibly delayed to near-instantaneous, human-AI collaboration shifts from “I give instructions, AI executes, I check” to “AI and I think and write together.” The former is asynchronous collaboration, the latter is synchronous collaboration. The product forms, use cases, and user retention of these two modes are on completely different levels.
For now, 400 tokens/s still needs independent benchmark verification, and TileRT is not yet fully open to all developers. But in terms of technical direction, it points to an important path: when inference latency becomes the core bottleneck, the focal point of optimization will shift from “making each computation step faster” to “keeping the entire computation flow unbroken.” Static compile-time orchestration, optimizing the entire model as a single whole, and keeping the GPU running continuously instead of starting and stopping frequently — these ideas may appear in more inference engine roadmaps over the next year or two.
There is a key difference between the inference speed competition and the inference cost competition: costs have a floor — approaching the cost of electricity; speed’s ceiling is defined by the physical limits of hardware, and that ceiling is still very high. The table in TileRT’s blog: the theoretical upper limit is about 1000 tokens/s, current production is about 400 tokens/s — there’s still 2.5x headroom. And this doesn’t even account for the bandwidth improvements from the next generation of hardware.
If this direction receives sustained investment, over the next year or two we may see frontier model inference speeds widely breaking through 200 tok/s, with fast mode becoming standard rather than a separately charged premium feature. Just like how GPT-4-level capabilities went from “needing to apply for access” to being “available at your fingertips.”