Over the past year or two, I've been dedicated to using AI to enhance writing and input efficiency, and I've genuinely experienced a qualitative boost in productivity. One key observation is that when we're writing articles or deep in thought, we might spend more than half of our time typing and correcting typos. This not only consumes time but, more importantly, disrupts our flow of ideas. A common issue during writing is the constant backtracking. You write a sentence, go back to fix a typo, and in the process, you forget what you wanted to say. After a few glances back, you finally remember and continue writing, only to fall back into the loop of correcting typos.
This is why, in the past couple of years, I developed a Telegram-based bot. You can talk directly to it, thinking aloud and voicing out your ideas simultaneously. Through this method, I found that it not only allows for quick voice input but, more importantly, it prevents typos from interrupting our thought process, enabling a smoother and deeper flow of ideas.
After using this bot, my workflow for thinking and writing underwent significant changes. Now, I tend to think out loud, recording my thoughts as I go. When my thoughts reach a certain stage, instead of reorganizing and rewriting the documents, I simply hand over the scattered results of voice recognition to AI. It then helps me organize them into a coherent technical document that can be preserved and shared.
However, during this process, I encountered a major pain point: speed. On one hand, Telegram is an additional app I need to open, switch to the bot's page, and press the record button, which takes time. On the other hand, its recognition is relatively slow. It only starts voice recognition after I've completely finished speaking a segment. Sometimes, it even takes several minutes to get the results. Overall, while this tool is effective for heavy-duty writing, its long turnaround time makes it less suitable for lightweight scenarios like casual chats.
First Iteration: Integrating Real-Time API
Recently, OpenAI released their Real-Time API, the technology behind the new ChatGPT real-time voice conversations. I integrated this API with my existing system to create a web-based tool available at https://f.gpty.ai/. The code is open-sourced on https://github.com/grapeot/brainwave/.
After some experimentation, I found the experience to be excellent. On one hand, this tool sends the recorded voice to OpenAI in real-time as the user speaks. The processing starts immediately, so by the time the user finishes speaking, the voice recognition result is output almost instantly. This reduces the delay by dozens of times. For example, previously after spending fifteen minutes thinking out loud, I had to wait two or three minutes for the voice recognition results, often needing to retry due to timeouts. Now, it only takes a second or two for results to start popping out.
If this improvement was expected, another surprising benefit was the quality of voice recognition, which surpassed what I achieved with OpenAI's own Whisper or third-party models like AssemblyAI. Not only was the recognition noticeably more accurate, but it also handled mixed Chinese and English content exceptionally well. My understanding is that while Whisper isn't an LLM and its language model isn't as extensive as GPT's, using GPT for voice recognition might seem like overkill. However, it easily outperforms the currently mainstream, relatively smaller models dedicated to voice recognition.
After using it for a while, I realized that because this setup is faster and more agile than the Telegram Bot, I was more inclined to use it in lightweight applications, such as voice input during WeChat chats.
Despite the improvements, the experience wasn't perfect. Similar to Telegram, I still had to open a webpage, click a button, and then start speaking. Although this removed the step of selecting a contact, there was still a considerable gap compared to the ideal seamlessness.
Second Iteration: Deep Integration with iPhone
Is there a way to completely skip these cumbersome UI operations? Just press a button and start speaking? After some exploration, I found it's entirely possible. I made three changes:
First, I added a URL parameter to the web frontend. When the URL contains start=1, it automatically begins recording without the user having to press the record button manually.
Second, iOS has a feature called Shortcuts, which allows users to create and share simple programs. I wrote a one-line shortcut that opens the URL with start=1. When executed, it pops up Safari and immediately starts recording.
Third, for iPhone 15 and later models, there's a hardware Action Button. You can customize the system behavior when you long-press the Action Button. Here, we link it to the shortcut I created.
Now, the experience is streamlined: long-pressing the Action Button triggers the web frontend and starts recording automatically. You can begin speaking right away, making the experience significantly smoother compared to the previous Telegram or even web bookmark-based methods.
Third Iteration: Achieving Zero Latency with an App
After using it for a while, I felt good about the improvements but knew it could be even better. A major issue was the slight delay—about 2 seconds—from long-pressing the Action Button to the webpage loading and starting the recording. While this was a notable improvement, it still had a psychological impact during actual use.
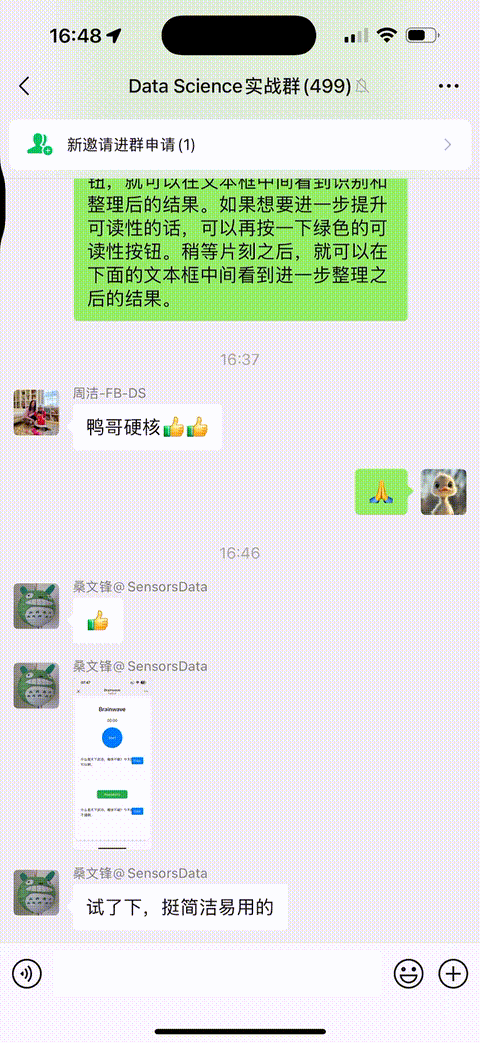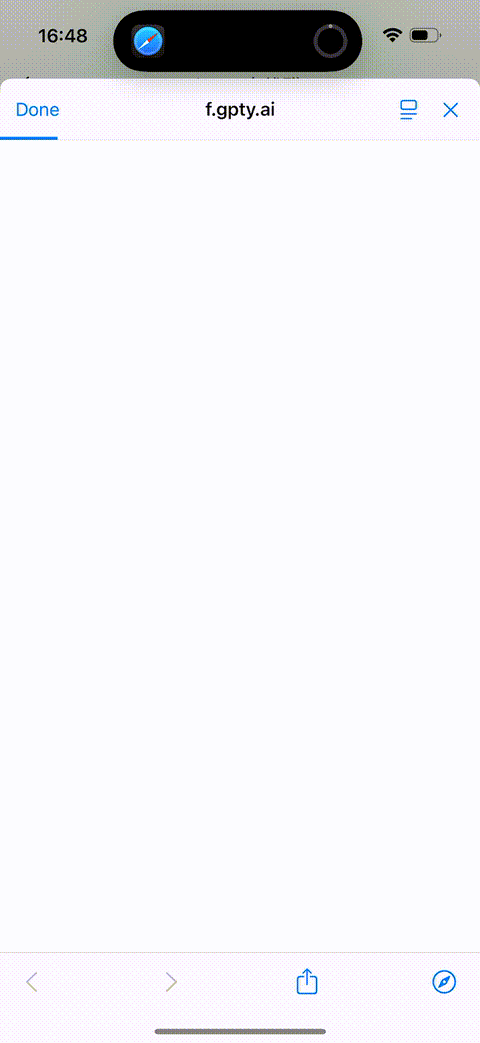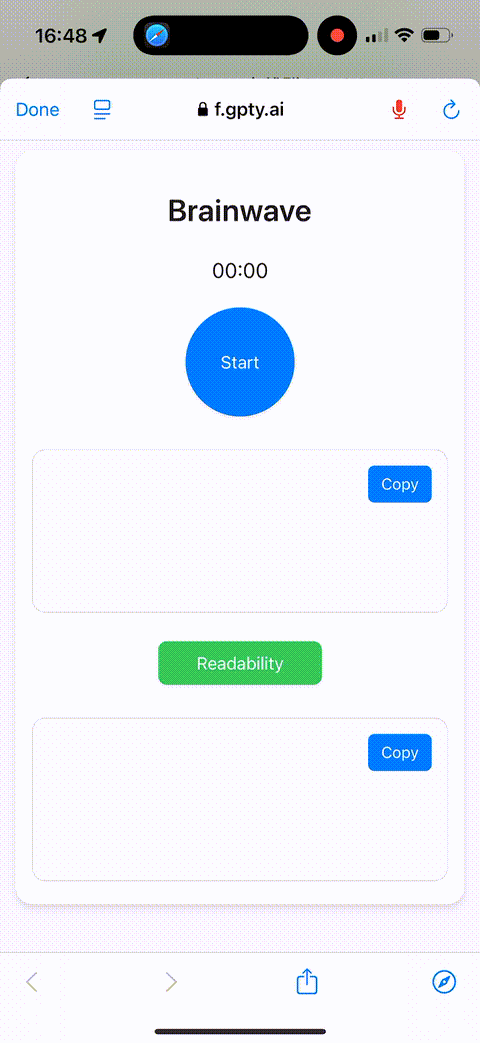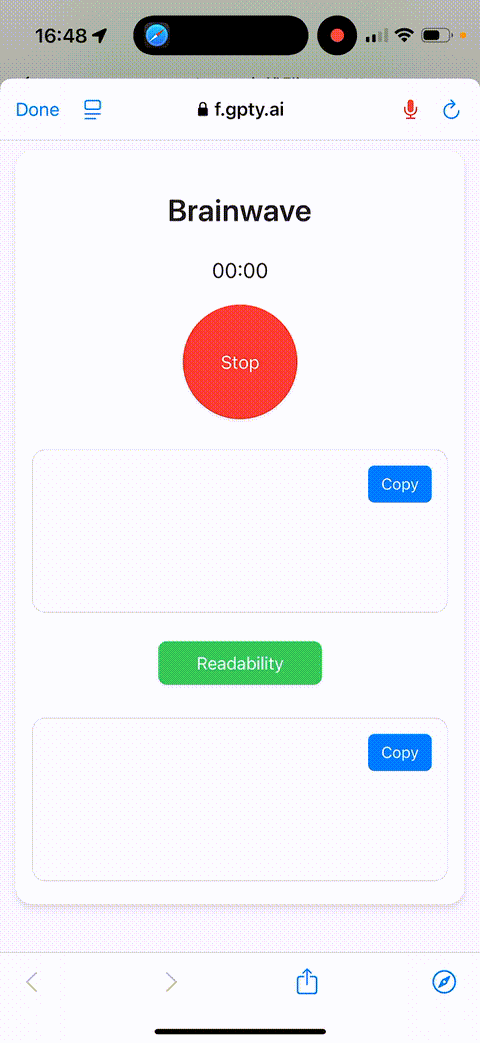
To optimize any issue, the first step is identifying the bottleneck. Here, the obvious culprits were downloading and rendering webpage content, initializing the microphone, and establishing a network connection. Except for the network connection, the other three could be preloaded. However, since we had to reload the webpage each time, many optimization methods were unusable.
A straightforward solution was to transform the webpage into an app. This way, it could run in the system background, avoiding the need to download the page, reinitialize the microphone, or even reconnect the network—resulting in lightning-fast response times. With a bit of thought, I developed an iOS client with Cursor's help. Besides caching various resources, this app did a few additional things:
First, it implemented a URL scheme similar to the web's start=1 parameter. When you long-press the Action Button, it uses this special URL scheme to call the app, which immediately starts recording without needing to press the record button manually.
Second, it leveraged Apple's Universal Clipboard. After speaking, the spoken text is automatically copied to the clipboard on all your Apple devices, including iPhone and Mac, without manually pressing a copy button as required by the web version. This introduced a new use case: while writing on a Mac, you can long-press the Action Button on your iPhone to summon the app, speak your thoughts, and then simply press Cmd + V on your Mac to paste the results immediately.
Third, to handle network issues—like when a long speech session fails due to connectivity problems—the app offers a resend function. You can choose to save the spoken words as an audio file in the Files app or resend them directly to the client, which is especially handy when the network is down.
Fourth, because the app is native, it supports localization. It automatically adapts to the user's system language for both Chinese and English, making the interface more user-friendly without affecting AI functionalities.
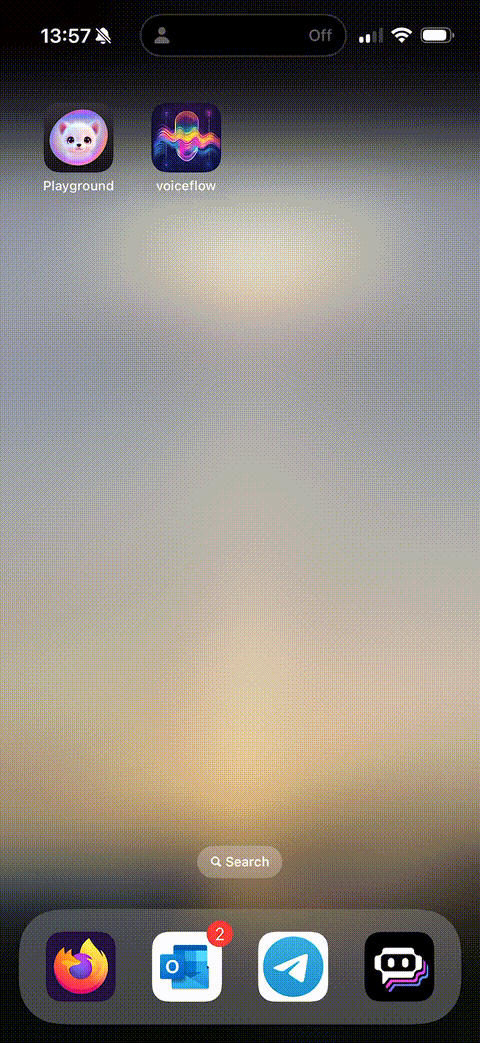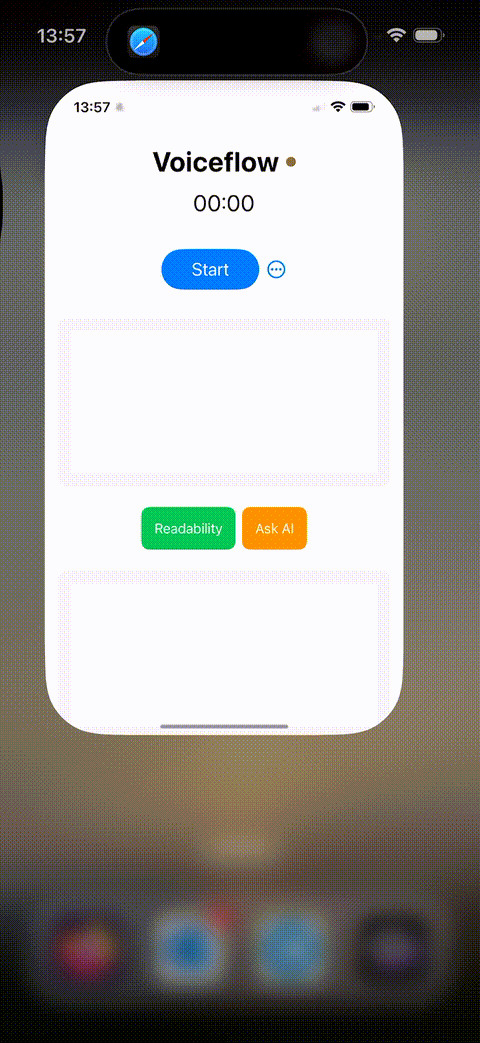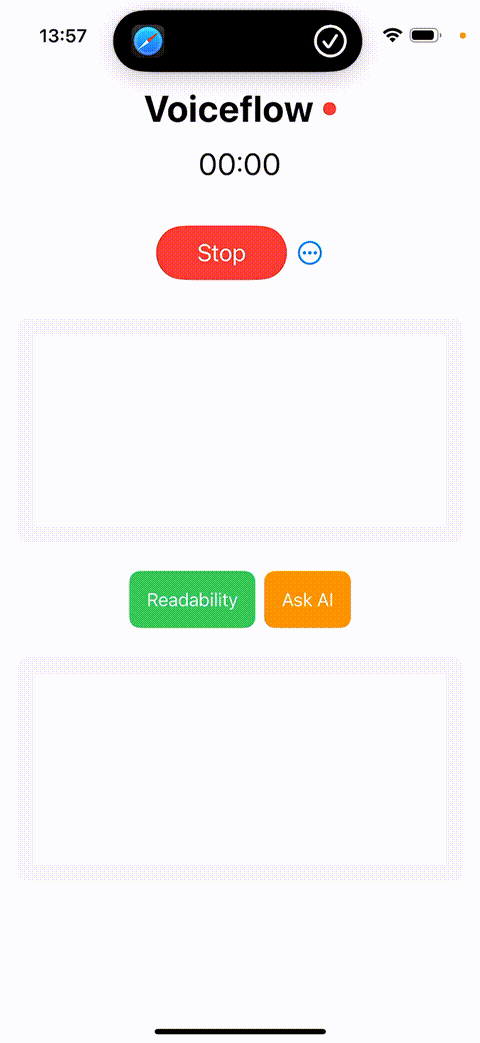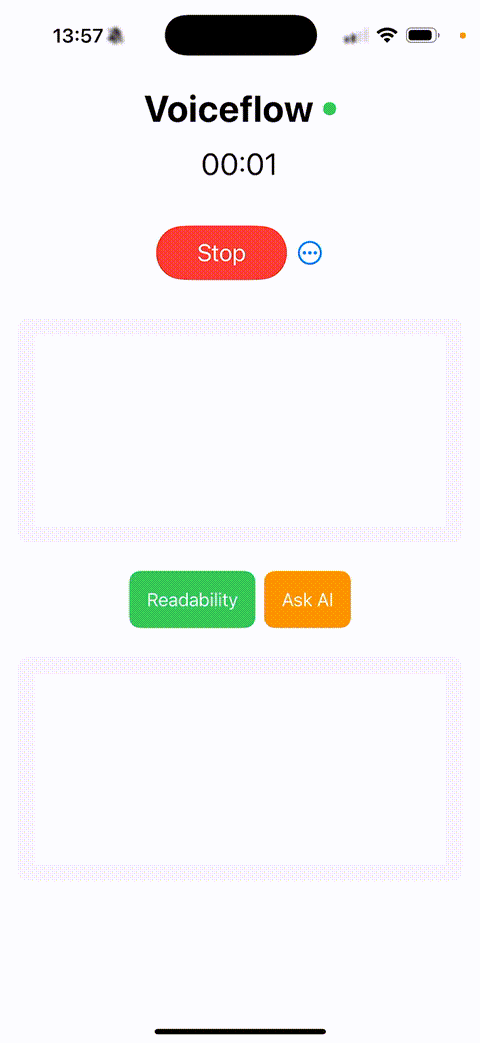
After these improvements, as shown in the above GIF, the entire system experienced a dramatic transformation in usability, robustness, and response time. A simple long-press of the Action Button almost instantly starts recording with virtually no delay. Moreover, the results are copied to the clipboard across all Apple devices, making them accessible anywhere—a highly convenient feature. Overall, this series of enhancements systematically elevated the user experience.
Pitfalls of Rapid Development with Cursor
I developed the entire process with Cursor's assistance, including integrating GPT API, FastAPI backend, web frontend, and the iOS app—all accomplished with Cursor in about eight hours. The API integration, backend, and web frontend took around three hours, while the remaining five hours were spent wrestling with iOS. Most of the time went into refactoring code for higher project quality rather than implementing features. The final code used the MVC architecture, with functions spread across multiple files for easy reuse and better logic. However, some details were time-consuming, such as OpenAI's requirement for API-uploaded files to have a 24kHz sampling rate. Both the web and iOS typically use 48kHz, making AI's adaptation challenging and leading to time wasted on correcting the correct code.
Overall, Cursor felt much more convenient than using Copilot or a barebones ChatGPT for coding. The key advantage was significantly reduced manual operations—no need to copy and paste constantly. With Cursor Composer, I didn't even have to manually create files or switch tabs; it handled those automatically. It even streamlined error handling by continuously invoking the linter and then the LLM to fix linter errors until the code could compile successfully.
Because of these three points, using Cursor to write code felt just as seamless as using the newly developed app for writing—allowing me to focus entirely on what I wanted to achieve without spending energy on typing for the LLM, copying and pasting code, creating files, or juggling error messages. However, this convenience comes with a downside: it's tempting to accept the AI-generated code without reviewing it, leading to potentially large, unintended changes that are hard to reverse.
There are two potential solutions to this problem. First, using Git acts like a time machine, allowing you to revert changes. Second, it's essential to keep reviewing the code it generates to ensure it matches your intentions. You don't need to scrutinize every detail, but a general check can help catch unwanted changes early. The fundamental principle is to manage and control the quality of AI-produced work, rather than passively accepting it and making ad-hoc corrections later.
Epilogue: Integrating Charging Features
As the story continues, after creating a tool that effectively aids thinking and accumulation using AI, many experts in my circle of friends are asking where they can download and use this app. The reason I haven't posted the app link yet is that this API is quite expensive, and I hope to add charging features to this app. This way, even if not for long-term profit, at least in the short term, it can help share the API's cost. However, after doing some system design, I quickly realized this is a very complex matter, much more complicated than I initially thought. Specifically, it mainly has the following difficulties:
First, to charge, you must have the concept of a user. But as soon as user management is involved, especially the storage of passwords, it involves many best practices in information security, such as salting, hashing, token authentication, etc. This requires a robust database configuration on one hand, and many coding techniques on the other. Whether using AI or not, a lot of effort is needed to ensure that these codes comply with best practices to ensure user information security.
The second issue is that even if user management is done well, sending them emails, including invoices, subscription notifications, refunds, etc., is also not a simple matter. I have indeed done some work on setting up SMTP servers for batch email sending, but such servers are easily considered spam by major email service providers. Avoiding this is not impossible, but it requires a lot of effort. Of course, there are many services like Mailgun or SendGrid for bulk email sending in the market, but their configuration and integration also take time.
The third difficulty lies in the payment itself, which is extremely complex. The current popular method in the market is integrating with payment service APIs like Stripe. But if you think about it carefully, you'll find that there are many details to handle, such as providing trials for new users, offering subscription services for old users, sending monthly invoices for subscriptions, timely renewal reminders, and sometimes refunds according to the law if users do not renew. Each of these functions requires separate integration with the API, and you may need to provide your own policies and web pages, which is particularly complex.
So overall, adding charging features to an app is something that sounds simple but is actually extremely complex. From this perspective, I suddenly understand why Apple takes a 30% cut from software on the App Store. One of the important benefits is that if I make an iOS app, I don't have to consider all these things, or at least I can choose not to.
For user management, I can directly use Apple ID, and Apple will handle all the email verification, password management, and other services, giving me a verified user ID, which I can use to manage everything on the server side. In addition, for login, I can directly call features like Face ID, providing a great user experience. Regarding email, I don't have to worry; the sending of related documents is also handled by Apple. When I need to send newsletters or other marketing materials, I can also get each user's email and use software like Mailchimp for bulk sending. As for payment, it's even simpler; everything is solved by Apple, and I don't have to deal with any APIs. Whether it's renewal reminders, invoice sending, deductions, or refunds, everything is handled by Apple, and I just have to sit and collect the money.
From this perspective, I instantly understood why Apple can charge a 30% "Apple tax." There is indeed a very high-value service here that can greatly shorten my go-to-market time. Of course, whether to choose to pay these development costs all at once or to slowly pay 30% of the revenue depends on different companies and different products. At least for products like mine, which currently do not see a particularly large market and need rapid trial and iteration, it is very attractive.